

Viettel đấu giá thành công quyền sử dụng tần số "đặc biệt quan trọng" cho mạng 4G và 5G
(Canhsatbien.vn) - TP. Hồ Chí Minh, ngày 23/4/2025, Tập đoàn Công nghiệp – Viễn thông Quân đội (Viettel) tổ chức Lễ khởi công Trung tâm dữ liệu & Nghiên cứu phát triển công nghệ cao Viettel tại Khu công nghiệp Tân Phú Trung, huyện Củ Chi, TP. Hồ Chí Minh. Đây sẽ là trung tâm dữ liệu (TTDL) quy mô siêu lớn, thuộc Top 10 khu vực Đông Nam Á.
20/05/2025 10:08:00 AM
Xem tiếp...
![[Bùng nổ ưu đãi] Đổi điểm Viettel++ - "Lên đời" Modem Wifi 6 miễn phí](http://old.canhsatbien.vn/upload/files/image/20250521/114_e1baa2nh20thumb-105433702.jpg?w=281)
[Bùng nổ ưu đãi] Đổi điểm Viettel++ - "Lên đời" Modem Wifi 6 miễn phí
(Canhsatbien.vn) - Đổi 5.000 điểm Viettel++ rinh ngay Modem Wifi 6! Chương trình tri ân khách hàng FTTH của Viettel, áp dụng trên My Viettel từ 07/05/2025 - 31/12/2025. Kiểm tra điều kiện và đổi điểm ngay!
19/05/2025 09:54:00 AM
Xem tiếp...

Viettel khởi động chương trình 'ươm mầm' lãnh đạo tương lai
(Canhsatbien.vn) - Viettel khởi động Viettel Future Changemakers 2025 từ 10/5, tạo điều kiện để tài năng trẻ có cơ hội dẫn dắt dự án, sản phẩm trọng điểm của tập đoàn.
14/05/2025 01:48:00 PM
Xem tiếp...

Viettel dẫn đầu về tốc độ mạng di động tháng 4/2025
(Canhsatbien.vn) - Viettel dẫn đầu về tốc độ mạng di động trong tháng 4/2025 trong bối cảnh chất lượng mạng di động băng rộng cả nước ghi nhận mức cải thiện mạnh mẽ nhất kể từ tháng 2/2024.
09/05/2025 09:54:00 AM
Xem tiếp...

Công nghệ Việt nhận diện chữ viết tay: Từ giải thưởng VIFOTEC đến ứng dụng đời sống
(Canhsatbien.vn) - Từ lâu, việc trích xuất thông tin từ hình ảnh văn bản, đặc biệt là tài liệu có bảng biểu không phân tách, chữ viết tay, định dạng phi chuẩn…, vẫn là một bài toán nan giải trong giới công nghệ. Các tập đoàn công nghệ lớn như Google, Microsoft, Amazon đã phát triển nhiều hệ thống nhận diện ký tự quang học và xử lý ngôn ngữ tự nhiên mạnh mẽ nhưng phần lớn chỉ tối ưu cho tiếng Anh và một số ngôn ngữ phổ biến. Với tiếng Việt, một ngôn ngữ có hệ thống dấu phong phú, cấu trúc ngữ âm đa tầng, các hệ thống quốc tế thường cho kết quả với độ chính xác chưa cao, đặc biệt trong xử lý chữ viết tay.
08/05/2025 01:56:00 PM
Xem tiếp...

Viettel tri ân khách hàng và tăng cường sóng 5G phục vụ dịp Đại lễ
(Canhsatbien.vn) - Hướng tới Đại lễ kỷ niệm 50 năm Ngày Giải phóng miền Nam và Ngày Quốc tế Lao động 1/5, Viettel Telecom đã huy động gần 1.000 cán bộ kỹ thuật và bổ sung hàng trăm điểm phát sóng mới, đặc biệt tăng cường vùng phủ sóng 5G nhằm đảm bảo chất lượng mạng lưới phục vụ người dân, du khách và các hoạt động trọng điểm.
29/04/2025 04:07:00 PM
Xem tiếp...
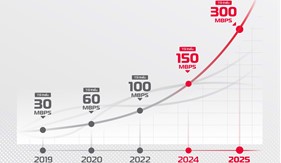
Viettel nâng băng thông cho toàn bộ khách hàng cũ lên tối thiểu 300mbps
(Canhsatbien.vn) - Cùng với việc ra mắt các gói cước Internet có băng thông tối thiểu từ 300 Mbps áp dụng cho khách hàng mới, từ tháng 4/2025, Viettel Telecom đã thực hiện nâng băng thông cho toàn bộ các gói cước Internet của khách hàng cũ lên tốc độ tối thiểu 300Mbps với mức giá ưu đãi chỉ từ 165.000 đồng/tháng (gói Internet đơn lẻ) và 185.000 đồng/tháng (gói combo Internet, Truyền hình).
26/04/2025 10:55:00 AM
Xem tiếp...

Viettel phát động chương trình “Yêu nước theo cách của bạn”
(Canhsatbien.vn) - Ngày 25/4, hòa chung không khí hào hùng kỷ niệm 50 năm Ngày Giải phóng miền Nam, thống nhất đất nước (30/4/1975 - 30/4/2025) và 80 năm Ngày Quốc khánh nước CHXHCN Việt Nam (2/9/1945 - 2/9/2025), TV360 - Ứng dụng nội dung số của Tổng Công ty Viễn Thông Viettel chính thức phát động Chương trình “Yêu nước theo cách của bạn” với thông điệp: Mỗi người một cách thể hiện, cùng tạo nên bản đồ 360 độ yêu nước đủ đầy, toàn diện và không giới hạn.
25/04/2025 08:37:00 PM
Xem tiếp...

Viettel Construction tiếp tục góp mặt trong Top 10 Nhà thầu uy tín năm 2025
(Canhsatbien.vn) - Viettel Construction tiếp tục được vinh danh trong Top 10 Nhà thầu Xây dựng Hạ tầng – Công nghiệp Uy tín năm 2025. Đây là năm thứ 2 liên tiếp Viettel Construction giữ vững thứ hạng cao trong ngành, minh chứng rõ ràng cho chiến lược phát triển bền vững, năng lực thi công vượt trội và uy tín thương hiệu ngày càng được khẳng định.
25/04/2025 10:57:00 AM
Xem tiếp...

Viettel nhận hai giải thưởng về nhân sự
(Canhsatbien.vn) - Viettel được vinh danh ở hạng mục "Thu hút nhân tài" và "Đào tạo & Phát triển nhân viên" nhờ nỗ lực xây dựng môi trường và phát triển nhân tài toàn diện tại HR Excellence Awards.
24/04/2025 01:58:00 PM
Xem tiếp...
Theo gương Bác
- Hải đội 102 kịp thời ứng cứu người dân bị tai nạn giao thông
- Đảng viên trẻ hăng say với công tác quần chúng
- 2 cá nhân của Cảnh sát biển Việt Nam tham gia Đại hội Thi đua yêu nước toàn quốc lần thứ XI
- Quân nhân Cảnh sát biển trả lại 150 triệu đồng của người dân chuyển nhầm
- Thư của Chính ủy Cảnh sát biển Việt Nam gửi Đoàn Tuyển thủ tham gia Hội thao Thể dục thể thao toàn quân năm 2025
- Thượng úy QNCN Nguyễn Bá Thanh - Người viết nên những dấu ấn trên chặng đường nỗ lực
Tuyên truyền Luật Cảnh sát biển Việt Nam
- Hơn 9.000 lượt dự thi trực tuyến “Tìm hiểu Luật Cảnh sát biển Việt Nam”
- Bộ Tư lệnh Vùng Cảnh sát biển 2 tổng kết và trao giải Cuộc thi “Tìm hiểu pháp luật”
- Tăng cường tuyên truyền pháp luật cho thanh niên
- Đẩy mạnh tuyên truyền pháp luật cho giáo dân khu vực Thuỷ Nguyên, Hải Phòng
- Đoàn Trinh sát số 1 đẩy mạnh tuyên truyền, phổ biến giáo dục pháp luật cho ngư dân
- Tuyên truyền pháp luật tại thị xã Hoài Nhơn, tỉnh Bình Định
Cuộc thi "Em yêu biển đảo quê hương"
- Hấp dẫn, gay cấn trong Cuộc thi “Em yêu biển đảo quê hương” tại tỉnh Gia Lai
- Sôi nổi vòng thi cấp tỉnh Cuộc thi “Em yêu biển, đảo quê hương” tại An Giang
- Sôi nổi Cuộc thi “Em yêu biển, đảo quê hương” tại Quảng Trị
- Cuộc thi “Em yêu biển, đảo quê hương”: Sôi nổi vòng thi cấp thành phố Huế
- Học sinh Quảng Ngãi hưởng ứng Cuộc thi “Em yêu biển, đảo quê hương”
- Lan tỏa tình yêu biển, đảo qua Cuộc thi “Em yêu biển, đảo quê hương” tại Đồng Tháp và Vĩnh Long
Khiên xanh giữ biển trên vùng biển phía Tây Nam
Khiên xanh giữ biển trên vùng biển phía Tây Nam
Xem tất cả...
Thông tin thời tiết
Nhiệt độ
Độ ẩm




Thống kê truy cập
![]() Thành viên trực tuyến: 0
Thành viên trực tuyến: 0
![]() Hôm nay: 5000
Hôm nay: 5000
![]() Hôm qua: 0
Hôm qua: 0
![]() Tháng này: 5000
Tháng này: 5000



